Talking Vehicles: Towards Natural Language Communication for Cooperative Autonomous Driving via Self-Play
Abstract
Past work has demonstrated that autonomous vehicles can drive more safely if they communicate with one another than if they do not. However, their communication has often not been human-understandable. Using natural language as a vehicle-to-vehicle (V2V) communication protocol offers the potential for autonomous vehicles to drive cooperatively not only with each other but also with human drivers. In this work, we propose a suite of traffic tasks in autonomous driving where vehicles in a traffic scenario need to communicate in natural language to facilitate coordination in order to avoid an imminent collision and/or support efficient traffic flow. To this end, this paper introduces a novel method, LLM+Debrief, to learn a message generation and high-level decision-making policy for autonomous vehicles through multi-agent discussion. To evaluate LLM agents for driving, we developed a gym-like simulation environment that contains a range of driving scenarios. Our experimental results demonstrate that LLM+Debrief is more effective at generating meaningful and human-understandable natural language messages to facilitate cooperation and coordination than a zero-shot LLM agent.
TalkingVehiclesGym
TalkingVehiclesGym is a multi-agent gymnasium simulation environment for the closed-loop evaluation of urban driving policies. It is designed to evaluate the performance of multi-agent communication and collaboration for an array of cooperative driving tasks. TalkingVehiclesGym supports in-episode communication in among autonomous agents through MQTT.

LLM+Debrief Learn to Collaborate using Natural Language via Self-Play
We ask the key research question that whether the current LLM agents are able to coordination well in the driving task without pre-coordination, and whether their cooperation capability could be improved over interactions. We start from building an agent that only rely on Chain-of-Thought, gradually extending to self-reflections and centralized discussions (LLM+Debrief) to create knowledge for future driving and collaborations.
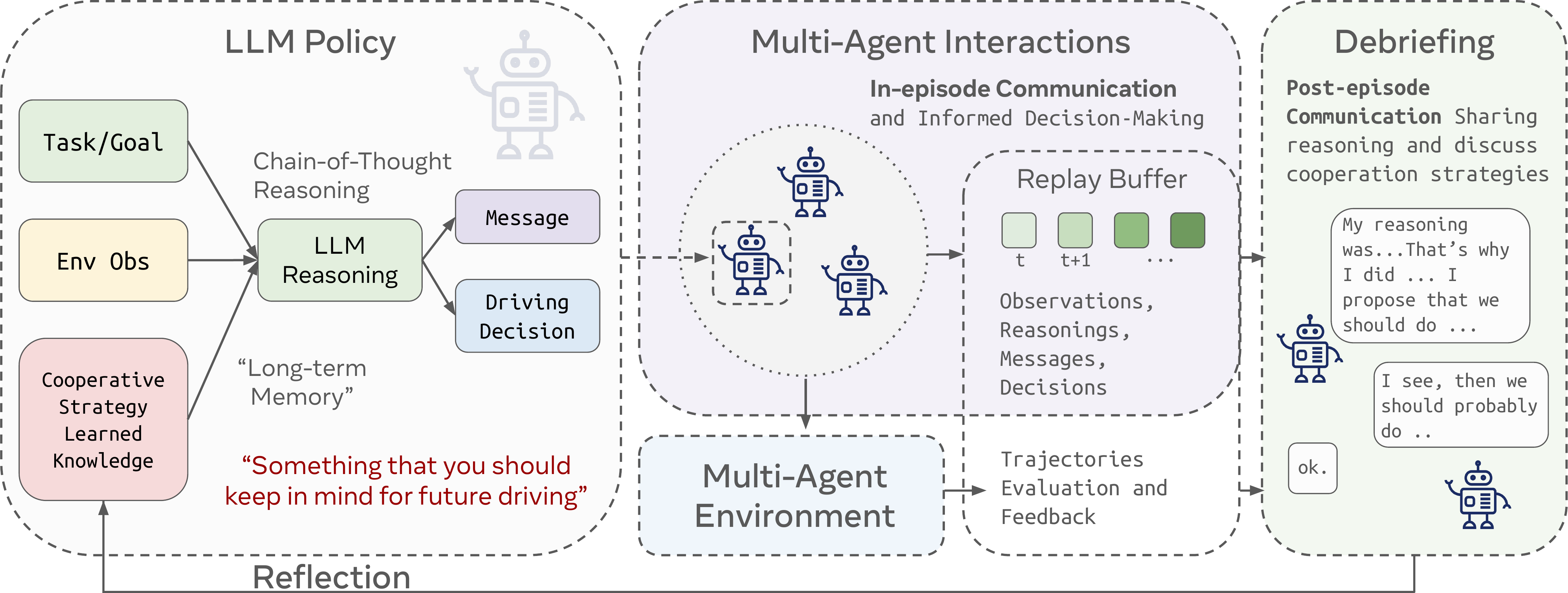
Agent Policy
The agent's probability distribution among actions is decided by an LLM with a prompt that contains the observations, tasks, traffic rules, received messages from other vehicles, and other important information for driving. The agent output must be in the json format that decides a command and/or a message to send.
-
In-Context Knowledge
Since the language models are auto-regressive, the probability of taking action is affected by the context provided to the agents. Thus, we can augment the prompt with the prior knowledge to alter the policy.
-
Chain-of-Thought Reasoning
We prompt the agent to reason about its surrounding and possible consequence of each action first, then then serve the output reasoning as a part of the prompt for final decisions.
Agent Learning
Initially, the LLM agents interact with each other in the scenarios and store their experience in the relay buffer. The agents then enage in a discussion session where they sample past experience as a context to refine their joint cooperative strategy.
-
Replay Buffer
We store the transition data (observations, actions, next observations) in a replay buffer. When an episode concludes, the environment will each agent's performance and provide scalar rewards, as well as verbal feedbacks like "Vehicle 109 collided with Vehicle 110 after 2 seconds" or "Vehicle 111 stagnated for too long to complete its task." Each transition data is retrospectively labeled with enriched meta data, including responses from other agents, collision details, stagnaition specifics and final outcomes.
-
Batch Sampling
While analyzing the entire trajectory would provide a comprehensive understanding of failure cases, computational constraints necessitate sampling a subset (batch) of keyframes from its replay buffer. To prioritize relevant data, the sampling process heuristically assigns higher probabilities to transitions that occur immediately before collisions, involve actions contributing to collisions, or lead to stagnation due to agents slowing down. Additionally, transitions that feature more intensive multi-agent interactions are given more weight.
-
Debrief
A debriefing session begins when an episode concludes in failure (collision or stagnation) and is conducted in a turn-based manner over N rounds, with a focus on improving cooperation in future interactions. The speaking order is deterministic in this work for each session, and agents take turns speaking in a round-robin format. The agent chosen to speak first is responsible for proposing a joint cooperative strategy for everyone participating in the debriefing (the focal group). This agent begins by reasoning through its transition data batch, analyzing the consequences and influence on other agents of its actions, and formulating a proposed strategy. Subsequently, the other agents take turns sharing their perspectives, providing feedback, or offering alternative insights based on their analysis of their own experience batch. After the discussion, each agent summarizes the discussion to develop individual cooperative strategies and knowledge. These outcomes serve as in-context guidelines for future driving tasks. This joint discussion for future individual decision-making structure mirrors the principles of the Centralized Training Decentralized Execution (CTDE) framework.
Experiments
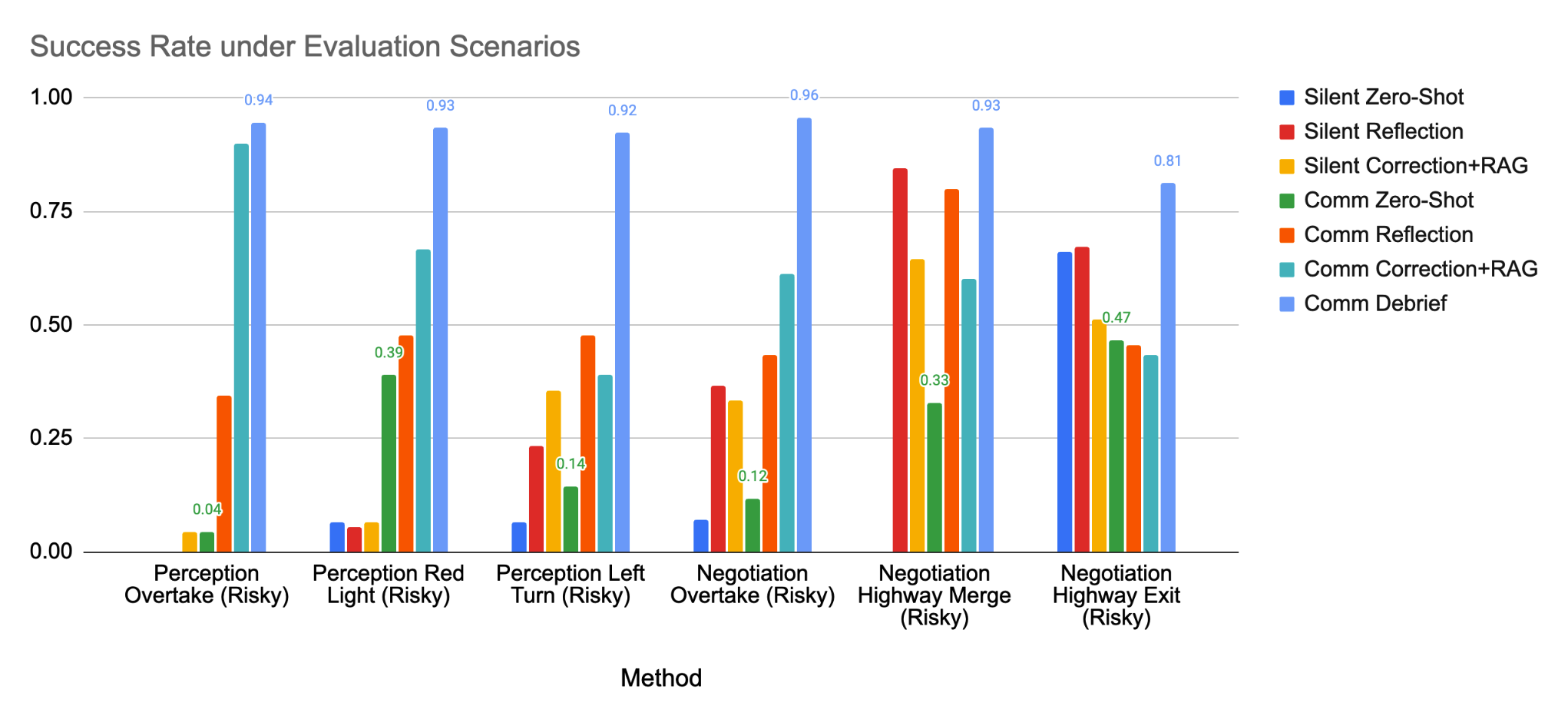
We established several baselines and scenarios to answer the research questions:
- Zero-shot: an LLM agent using Chain-of-Thought (CoT) reasoning only.
- Reflection: an LLM agent with CoT reasoning contextualized with knowledge from decentralized reflection.
- Correction+RAG: an LLM agent that corrects past actions via self-reflection, stores these corrections in a vector-based retrievable memory, and uses few-shot retrieved-example augmented generation.
- Correction+RAG (Silent): the retrieval-augmented method without communication (adapting DiLU, a non-communicating single-agent LLM-based reflection-driving approach, to our environment).
- Correction+RAG (Comm): the multi-agent communication extension of DiLU (AgentsCoDriver), which resembles Correction+RAG but does not actively optimize the messages.
For a fair comparison across these LLM-based baselines, we did not initialize any knowledge with human data, nor was there human involvement during the learning process.
Qualitative Videos
Scenario 1: Perception Overtake
Scenario 2: Perception Red Light
Scenario 3: Perception Left Turn
Scenario 4: Negotiation Overtake
Scenario 5: Negotiation Highway Merge
Scenario 6: Negotiation Highway Exit
Example Learned Knowledge
Perception Overtake
Car1 (Overtaking), Vehicle 197
In our refined cooperative strategy, the stationary vehicle in lane 1 will continuously monitor lane -1 for any approaching traffic and provide real-time alerts. Meanwhile, the overtaking vehicle will actively use its sensors to independently verify the status of lane -1. If both the stationary vehicle's observations and the overtaking vehicle's sensors confirm that lane -1 is clear, the overtaking vehicle will promptly proceed with the maneuver to avoid stagnation. If the stationary vehicle detects any traffic in lane -1, it will immediately communicate this, advising the overtaking vehicle to hold its position. The overtaking vehicle will remain ready to accelerate smoothly once the lane is confirmed clear. This dual-verification approach, combining sensor data and real-time communication, ensures a timely and safe overtaking maneuver, preventing collisions and minimizing stagnation.
Truck (Stopped Truck in Lane 1), Vehicle 199
In our refined cooperative strategy, as the stationary truck in lane 1, I will continuously monitor lane -1 for any approaching traffic and provide immediate alerts if I detect any vehicles, advising the overtaking vehicle to hold its position. Meanwhile, the overtaking vehicle will actively use its sensors to independently verify the status of lane -1. If both my observations and the overtaking vehicle's sensors confirm that lane -1 is clear, the overtaking vehicle should promptly proceed with the overtaking maneuver to avoid stagnation. This dual-verification approach, combining sensor data and real-time alerts, ensures a timely and safe overtaking maneuver, preventing collisions and minimizing stagnation.
Perception Red Light
Car1 (Proceeding Forward with Green Lights), Vehicle 109
In our cooperative strategy, the vehicle with the best view of the intersection, typically positioned to turn left, will lead in monitoring and communicating updates about potential threats. This vehicle will provide real-time information about any approaching vehicles against a red light, including their distance and speed, and confirm when they have stopped or are no longer a threat. If a threat is detected, the vehicle with the green light, ready to proceed straight through the intersection, should remain stationary until the intersection is confirmed clear. The monitoring vehicle will send updates every few seconds to keep all vehicles informed. Once the threat is resolved, the monitoring vehicle will confirm the intersection is clear, allowing the vehicle with the green light to proceed promptly and safely. This plan ensures safety by preventing collisions and minimizes unnecessary delays by enabling vehicles to pass through the intersection efficiently when it is safe to do so.
Truck (Stopped at Intersection), Vehicle 117
In our cooperative strategy, the vehicle with the best view of the intersection, which is the stationary truck (myself), will lead in monitoring and communicating updates about potential threats. If a vehicle is detected approaching against a red light, I will immediately alert all vehicles, providing specific information about the threat's distance and speed. The vehicle with the green light, positioned to proceed straight through the intersection, should remain stationary until I confirm that the threat has stopped or is no longer present. I will send updates every few seconds to keep all vehicles informed. Once the intersection is clear, I will confirm this, allowing the vehicle with the green light to proceed promptly and safely. This plan ensures safety by preventing collisions and minimizes unnecessary delays by enabling vehicles to pass through the intersection efficiently when it is safe to do so.
Perception Left Turn
Car1 (Northbound Left Turning), Vehicle 109
In our revised cooperative strategy, the stationary vehicle at the intersection will continuously monitor the traffic flow and provide real-time updates to both the left-turning vehicle (myself) and the oncoming vehicle. The stationary vehicle will send a message advising me to slow down and assess the situation, ensuring I only proceed with the left turn when I receive confirmation that the oncoming vehicle has acknowledged the yield instruction. Simultaneously, the stationary vehicle will instruct the oncoming vehicle to yield and adjust its speed to allow me to pass safely. If the oncoming vehicle does not acknowledge or adjust its speed, the stationary vehicle will alert me to stop and wait until it is safe to proceed. This plan ensures that all vehicles are aware of each other's intentions, allowing me to make the left turn safely and efficiently without causing collisions or unnecessary stagnation.
Truck (Stopped at Intersection), Vehicle 111
In our revised cooperative strategy, as the stationary vehicle with a clear view of the intersection, I will continuously monitor the traffic flow and provide real-time updates to both the northbound left-turning vehicle and the oncoming vehicle. I will send a message to the left-turning vehicle advising it to slow down and assess the situation, ensuring it only proceeds when it receives confirmation that the oncoming vehicle has acknowledged the yield instruction. Simultaneously, I will send a message to the oncoming vehicle instructing it to yield and adjust its speed to allow the left-turning vehicle to pass safely. If the oncoming vehicle does not acknowledge or adjust its speed, I will alert the left-turning vehicle to stop and wait until it is safe to proceed. This plan ensures that all vehicles are aware of each other's intentions, allowing the left-turning vehicle to pass the intersection safely and quickly without causing collisions or unnecessary stagnation.
Negotiation Overtake
Car1 (Overtaking Car), Vehicle 197
In our cooperative strategy, when I, as the vehicle intending to overtake a stationary truck in my lane, need to move into the opposite lane, I will first send a message to the oncoming vehicle in the opposite lane, indicating my intention to overtake and requesting a temporary speed reduction to create a safe gap. The oncoming vehicle should acknowledge this request and, if feasible, slightly slow down to create a safe gap, but avoid coming to a complete stop to prevent stagnation. Once the gap is sufficient, I will proceed with the overtaking maneuver and return to my original lane as quickly and safely as possible. After completing the maneuver, I will send a confirmation message, allowing the oncoming vehicle to resume its target speed. This plan ensures that I minimize my time in the opposite lane while the other vehicle maintains its urgency, thus preventing collisions and avoiding stagnation. Effective communication and adaptive speed adjustments are key to ensuring both vehicles can complete their tasks safely and efficiently.
Car2 (Opposite Car), Vehicle 198
In our cooperative strategy, when a vehicle in the opposite lane intends to overtake a stationary vehicle and temporarily move into my lane, it should first send a message indicating its intention and request a temporary speed adjustment. As the vehicle tasked with going forward and keeping lane, I should acknowledge this request and, if feasible, slightly slow down to create a safe gap, but avoid coming to a complete stop to prevent stagnation. The overtaking vehicle should proceed with the maneuver as quickly and safely as possible, minimizing its time in my lane. Once the overtaking vehicle has safely returned to its original lane, it should send a confirmation message, allowing me to resume my target speed. This plan ensures that the overtaking vehicle minimizes its time in the opposite lane while I maintain my urgency, thus preventing collisions and avoiding stagnation. Effective communication and adaptive speed adjustments are key to ensuring both vehicles can complete their tasks safely and efficiently.
Negotiation Highway Merge
Car1 (Merging on to the Highway), Vehicle 120
In the cooperative strategy, as the merging vehicle, I will initiate communication by indicating my intention to merge onto the highway and requesting the vehicle directly to my left on the highway to create a gap by slightly slowing down or, if feasible, temporarily changing lanes. The highway vehicle should acknowledge this request and adjust its position accordingly, ensuring it maintains a safe distance. Meanwhile, I will adjust my speed to align with the newly created gap, ensuring I do not accelerate until the highway vehicle has stabilized its speed and distance. The vehicle behind the highway vehicle should maintain its speed or slightly slow down to prevent closing the gap prematurely. Continuous communication will be maintained, with updates on speed adjustments and intentions, to ensure all vehicles are aware of each other's actions. This approach will prevent collisions by ensuring a clear and sufficient gap for merging while avoiding stagnation by coordinating speed and lane adjustments effectively.
Car2 (Highway Vehicle), Vehicle 121
In the cooperative strategy, the merging vehicle should initiate communication by indicating its intention to merge onto the highway and requesting the highway vehicle directly to its left to create a gap by slightly slowing down. The highway vehicle, which is myself, should acknowledge this request and slightly reduce speed to create a safe merging space, while maintaining my lane and preparing to accelerate once the merge is complete. The merging vehicle should adjust its speed to align with the gap, ensuring it does not accelerate until I have stabilized my speed and distance. The vehicle behind me on the highway should maintain its speed or slightly slow down to prevent closing the gap prematurely. Continuous communication should be maintained, with updates on speed adjustments and intentions, to ensure all vehicles are aware of each other's actions. This approach will prevent collisions by ensuring a clear and sufficient gap for merging while avoiding stagnation by coordinating speed adjustments effectively.
Negotiation Highway Exit
Car1 (Exiting the Highway), Vehicle 120
In our cooperative strategy, as the vehicle in the high-speed lane intending to exit, I will initiate communication with the vehicle in the leftmost lane at least 100 meters before the exit junction, clearly indicating my intention to merge. If the vehicle in the leftmost lane is slightly ahead or side-by-side, it should decelerate slightly to create a gap ahead, allowing me to merge smoothly without causing stagnation. I will maintain a speed that allows me to observe the gap being created and will only proceed with the lane change once I have a clear visual confirmation of a safe gap. If the vehicle in the leftmost lane is stationary or unable to create a gap due to traffic conditions, it should communicate this status immediately. In such cases, I will adjust my speed to maintain a safe distance and seek an alternative gap or prepare to slow down significantly if necessary. Both vehicles should actively communicate their speed adjustments and confirm when a safe gap is established, ensuring that the lane change is executed without collision or stagnation.
Car2 (Leader of the Left Flow Staying on the Highway), Vehicle 121
In our cooperative strategy, when a vehicle in the adjacent lane intends to merge into the leftmost lane for a highway exit, it should initiate communication at least 100 meters before the exit junction, clearly indicating its intention to merge. As the vehicle currently in the leftmost lane, my responsibility is to promptly acknowledge this message and assess the traffic situation. If I am slightly ahead or side-by-side with the merging vehicle, I will decelerate slightly to create a gap ahead, allowing the merging vehicle to merge smoothly without causing stagnation. The merging vehicle should maintain a speed that allows it to observe the gap being created and only proceed with the lane change once it has a clear visual confirmation of a safe gap. If I am stationary or unable to create a gap due to traffic conditions, I will communicate this status immediately. In such cases, the merging vehicle should adjust its speed to maintain a safe distance and seek an alternative gap or prepare to slow down significantly if necessary. Both vehicles should actively communicate their speed adjustments and confirm when a safe gap is established, ensuring that the lane change is executed without collision or stagnation."
Distillation and Generalization
We perform full-parameter fine-tuning of a compact language model (DistilGPT2 Sanh et al., 2019) to directly imitate the behavior of our large, memory-augmented LLM+Debrief agent. To build the imitation dataset, we collect every successful evaluation episode across all six scenarios and record the large agent’s token-level outputs. The distillation model is then trained to minimize cross-entropy loss against those outputs. At inference time, it generates decisions via random sampling with a temperature of 0.2.
Each policy is evaluated with three random seeds (30 episodes per seed). We report the mean and ±1 SEM across seeds. Debrief (per-scenario) is an oracle baseline learned individually per scenario.
| Method | Overtake (Perception) | Red Light | Left Turn | |||
|---|---|---|---|---|---|---|
| CR (%) ↓ | SR (%) ↑ | CR (%) ↓ | SR (%) ↑ | CR (%) ↓ | SR (%) ↑ | |
| Debrief (per-scenario) | 1.1 ± 1.1 | 98.9 ± 1.1 | 0.0 ± 0.0 | 96.7 ± 0.0 | 4.4 ± 2.9 | 94.4 ± 2.2 |
| Centralized Memory | 2.2 ± 1.1 | 93.3 ± 1.9 | 0.0 ± 0.0 | 100.0 ± 0.0 | 4.4 ± 2.9 | 93.3 ± 3.3 |
| Distillation | 0.0 ± 0.0 | 83.3 ± 1.9 | 0.0 ± 0.0 | 91.1 ± 4.4 | 0.0 ± 0.0 | 96.7 ± 0.0 |
| Method | Overtake (Negotiation) | Highway Merge | Highway Exit | |||
| CR (%) ↓ | SR (%) ↑ | CR (%) ↓ | SR (%) ↑ | CR (%) ↓ | SR (%) ↑ | |
| Debrief (per-scenario) | 10.0 ± 3.8 | 87.2 ± 3.9 | 2.2 ± 2.2 | 97.8 ± 2.2 | 13.3 ± 6.0 | 86.7 ± 6.0 |
| Centralized Memory | 12.2 ± 2.9 | 86.7 ± 1.9 | 1.1 ± 1.1 | 98.9 ± 1.1 | 16.1 ± 4.8 | 82.8 ± 5.3 |
| Distillation | 10.0 ± 3.3 | 88.9 ± 4.4 | 0.0 ± 0.0 | 100.0 ± 0.0 | 3.3 ± 0.0 | 96.7 ± 0.0 |
Decision Latency & Message Size (Distilled LLM Policy)
| Latency / Scenario | Overtake | Left Turn | Red Light | Overtake | Highway Merge | Highway Exit |
|---|---|---|---|---|---|---|
| Decision Latency (s) | 0.45 | 0.44 | 0.38 | 0.14 | 0.19 | 0.20 |
| Message Size (bytes) | 223.3 | 297.9 | 223.0 | 28.0 | 59.0 | 59.0 |
Future Work
Talking Vehicles is a promising step towards AI agents that can purposefully communicate with each other and humans in a natural language to coordinate on a task via self-play among agents. Future work will be directed towards creating more robust and diverse learned policies to enable ad hoc teamwork, integrating larger multimodal models, and studying the learning methods that can train the agents to perform more complex tasks.
BibTeX
@misc{cui2025talkingvehicles,
title={Towards Natural Language Communication for Cooperative Autonomous Driving via Self-Play},
author={Jiaxun Cui and Chen Tang and Jarrett Holtz and Janice Nguyen and Alessandro G. Allievi and Hang Qiu and Peter Stone},
year={2025},
eprint={2505.18334},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2505.18334},
}